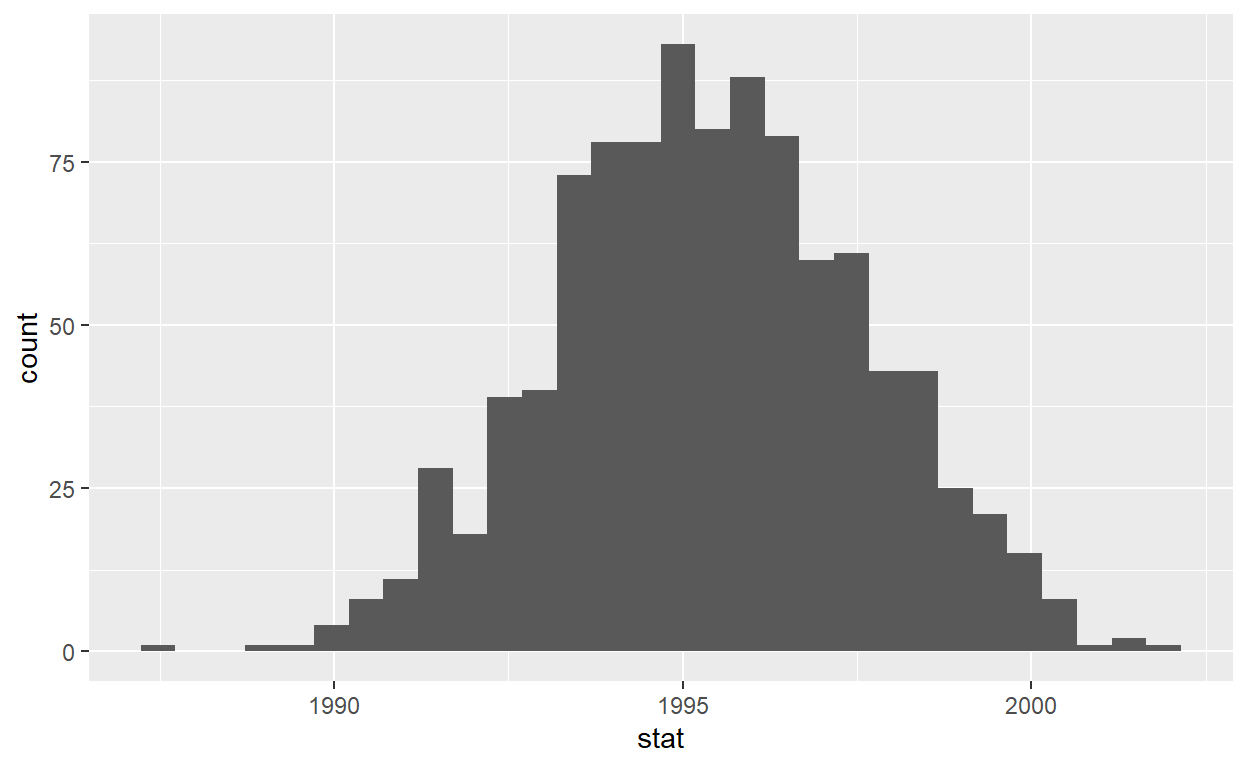
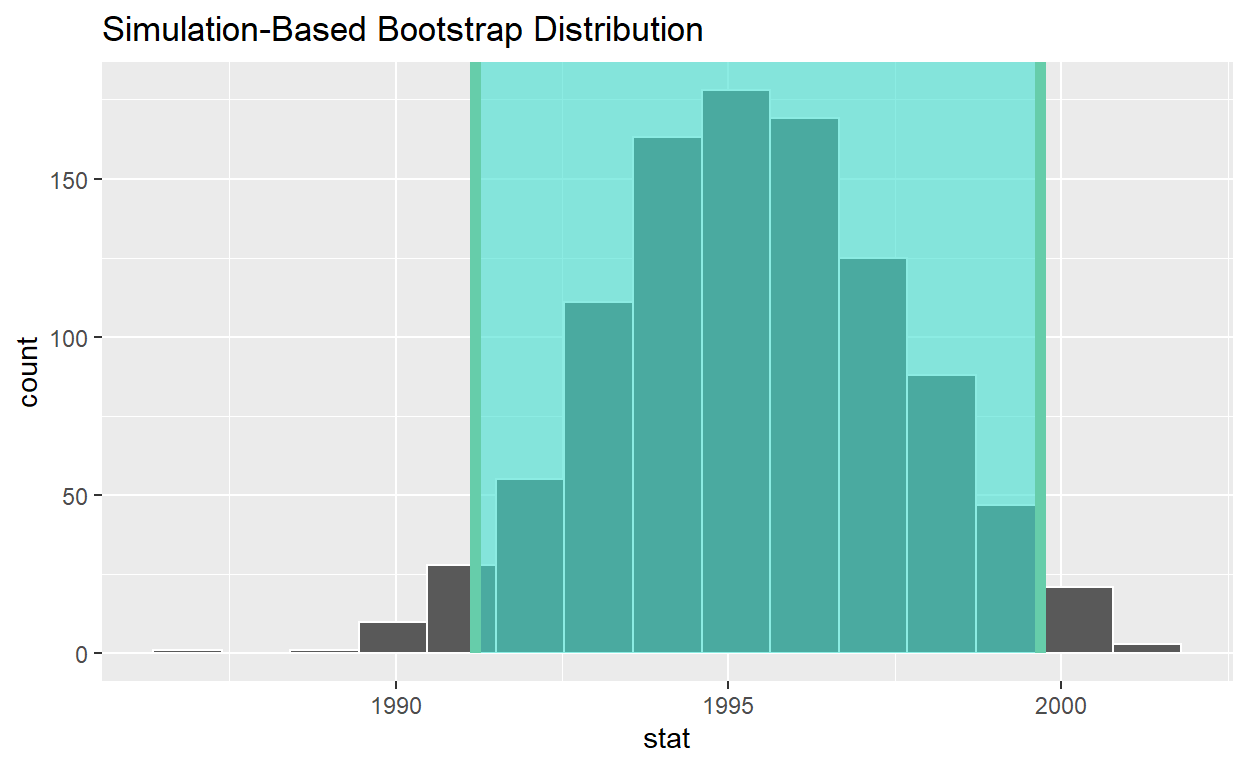
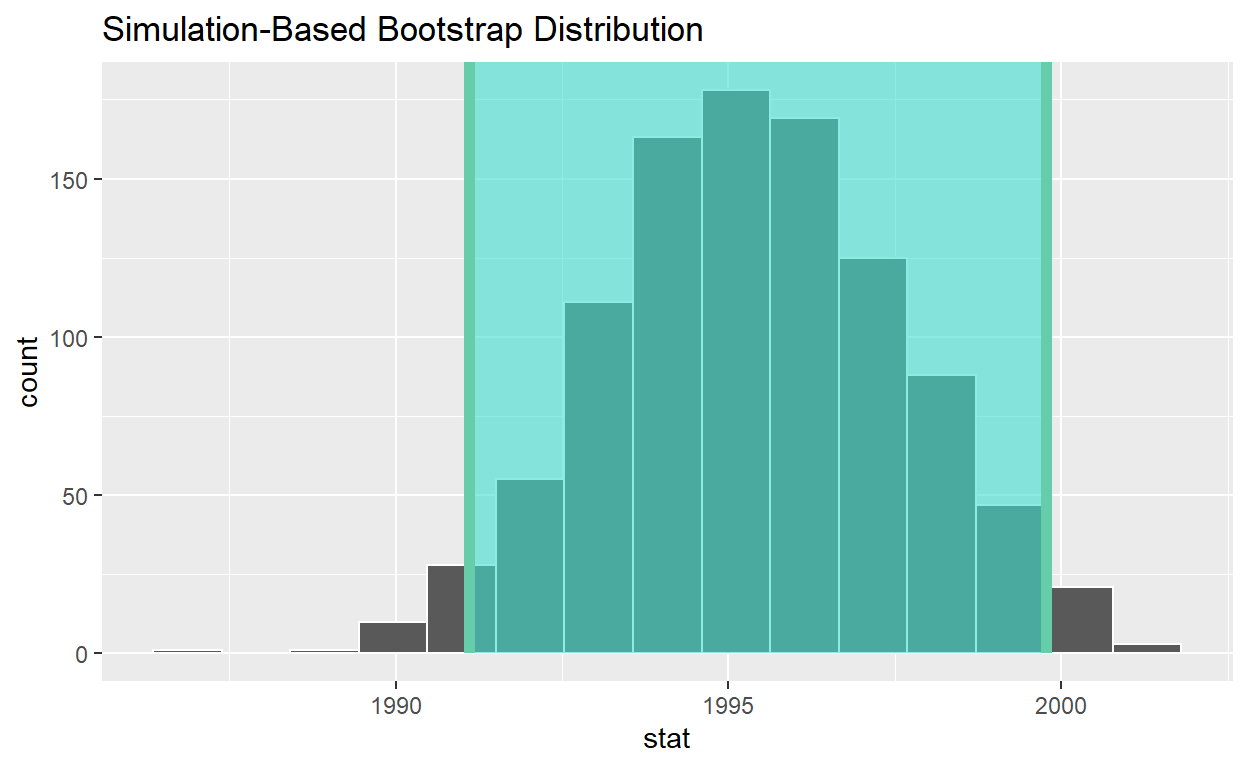
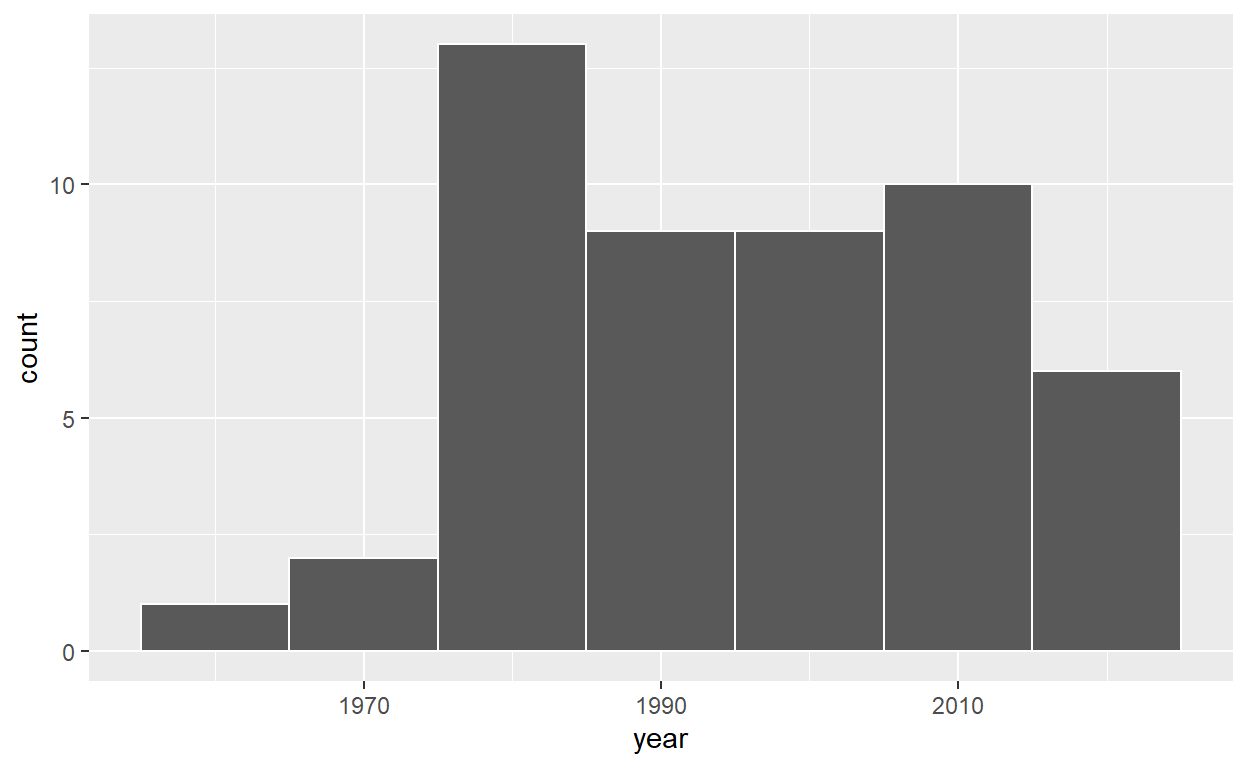# A tibble: 50 x 2
ID year
<int> <dbl>
1 1 2002
2 2 1986
3 3 2017
4 4 1988
5 5 2008
6 6 1983
7 7 2008
8 8 1996
9 9 2004
10 10 2000
# ... with 40 more rows
# A tibble: 1 x 1
mean_year
<dbl>
1 1995.
pennies_resample <- tibble(
year = c(1976, 1962, 1976, 1983, 2017, 2015, 2015, 1962, 2016, 1976,
2006, 1997, 1988, 2015, 2015, 1988, 2016, 1978, 1979, 1997,
1974, 2013, 1978, 2015, 2008, 1982, 1986, 1979, 1981, 2004,
2000, 1995, 1999, 2006, 1979, 2015, 1979, 1998, 1981, 2015,
2000, 1999, 1988, 2017, 1992, 1997, 1990, 1988, 2006, 2000)
)
# A tibble: 1 x 1
mean_year
<dbl>
1 1995.
# A tibble: 1,750 x 3
# Groups: name [35]
replicate name year
<int> <chr> <dbl>
1 1 Arianna 1988
2 1 Arianna 2002
3 1 Arianna 2015
4 1 Arianna 1998
5 1 Arianna 1979
6 1 Arianna 1971
7 1 Arianna 1971
8 1 Arianna 2015
9 1 Arianna 1988
10 1 Arianna 1979
# ... with 1,740 more rows
# A tibble: 35 x 2
name mean_year
<chr> <dbl>
1 Arianna 1992.
2 Artemis 1996.
3 Bea 1996.
4 Camryn 1997.
5 Cassandra 1991.
6 Cindy 1995.
7 Claire 1996.
8 Dahlia 1998.
9 Dan 1994.
10 Eindra 1994.
# ... with 25 more rows
ggplot(resampled_means, aes(x = mean_year)) +
geom_histogram(binwidth = 1, color = "white", boundary = 1990) +
labs(x = "Sampled mean year")
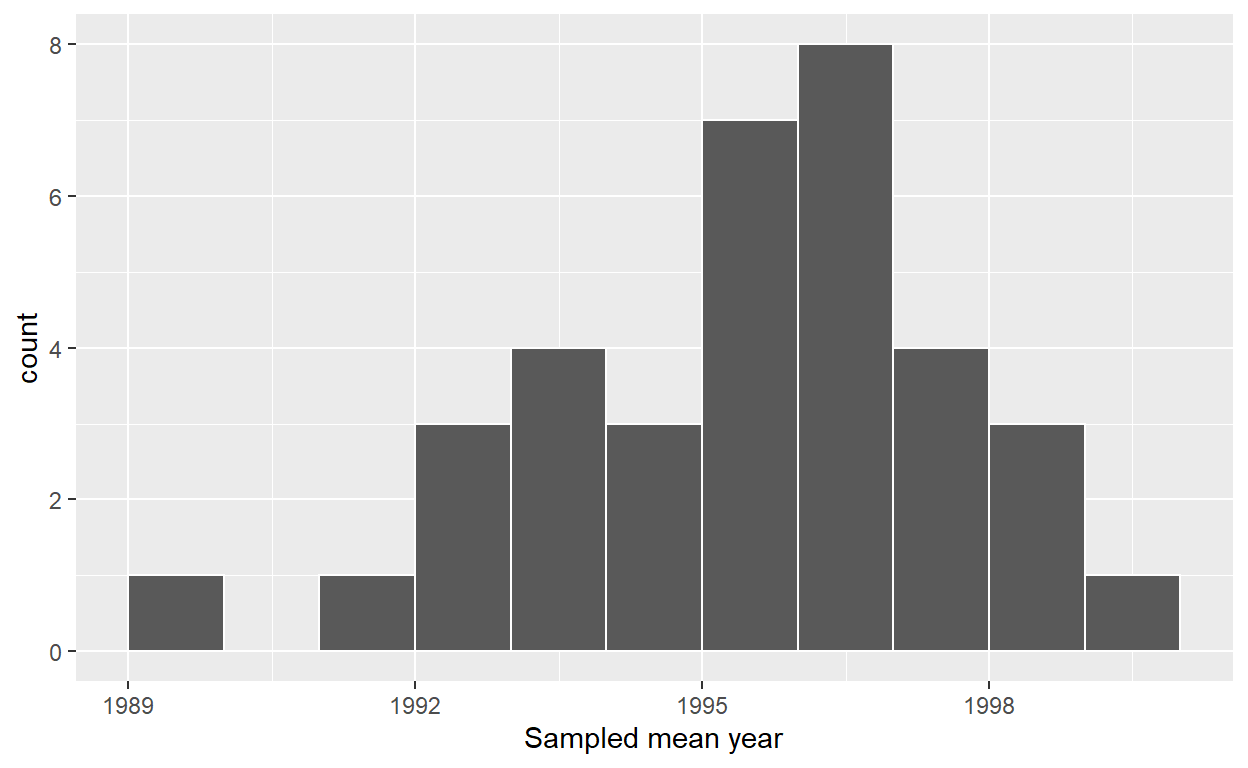
virtual_resample <- pennies_sample %>%
rep_sample_n(size = 50, replace = TRUE)
# A tibble: 50 x 3
# Groups: replicate [1]
replicate ID year
<int> <int> <dbl>
1 1 34 1985
2 1 47 1982
3 1 49 2006
4 1 47 1982
5 1 5 2008
6 1 24 2017
7 1 16 2015
8 1 12 1995
9 1 11 1994
10 1 35 1985
# ... with 40 more rows
# A tibble: 1 x 2
replicate resample_mean
<int> <dbl>
1 1 1995.
virtual_resamples <- pennies_sample %>%
rep_sample_n(size = 50, replace = TRUE, reps = 35)
virtual_resamples
# A tibble: 1,750 x 3
# Groups: replicate [35]
replicate ID year
<int> <int> <dbl>
1 1 41 1992
2 1 11 1994
3 1 2 1986
4 1 28 2006
5 1 7 2008
6 1 40 1990
7 1 5 2008
8 1 14 1978
9 1 3 2017
10 1 25 1979
# ... with 1,740 more rows
# A tibble: 35 x 2
replicate mean_year
<int> <dbl>
1 1 1996.
2 2 1991.
3 3 1999.
4 4 1994.
5 5 1994.
6 6 1990.
7 7 1993.
8 8 1993.
9 9 1995.
10 10 1998.
# ... with 25 more rows
ggplot(virtual_resampled_means, aes(x = mean_year)) +
geom_histogram(binwidth = 1, color = "white", boundary = 1990) +
labs(x = "Resample mean year")

# Repeat resampling 1000 times
virtual_resamples <- pennies_sample %>%
rep_sample_n(size = 50, replace = TRUE, reps = 1000)
# Compute 1000 sample means
virtual_resampled_means <- virtual_resamples %>%
group_by(replicate) %>%
summarize(mean_year = mean(year))
# A tibble: 1,000 x 2
replicate mean_year
<int> <dbl>
1 1 2000.
2 2 1996.
3 3 1993
4 4 1995.
5 5 1994.
6 6 1995.
7 7 1996.
8 8 1994.
9 9 1997.
10 10 1994.
# ... with 990 more rows
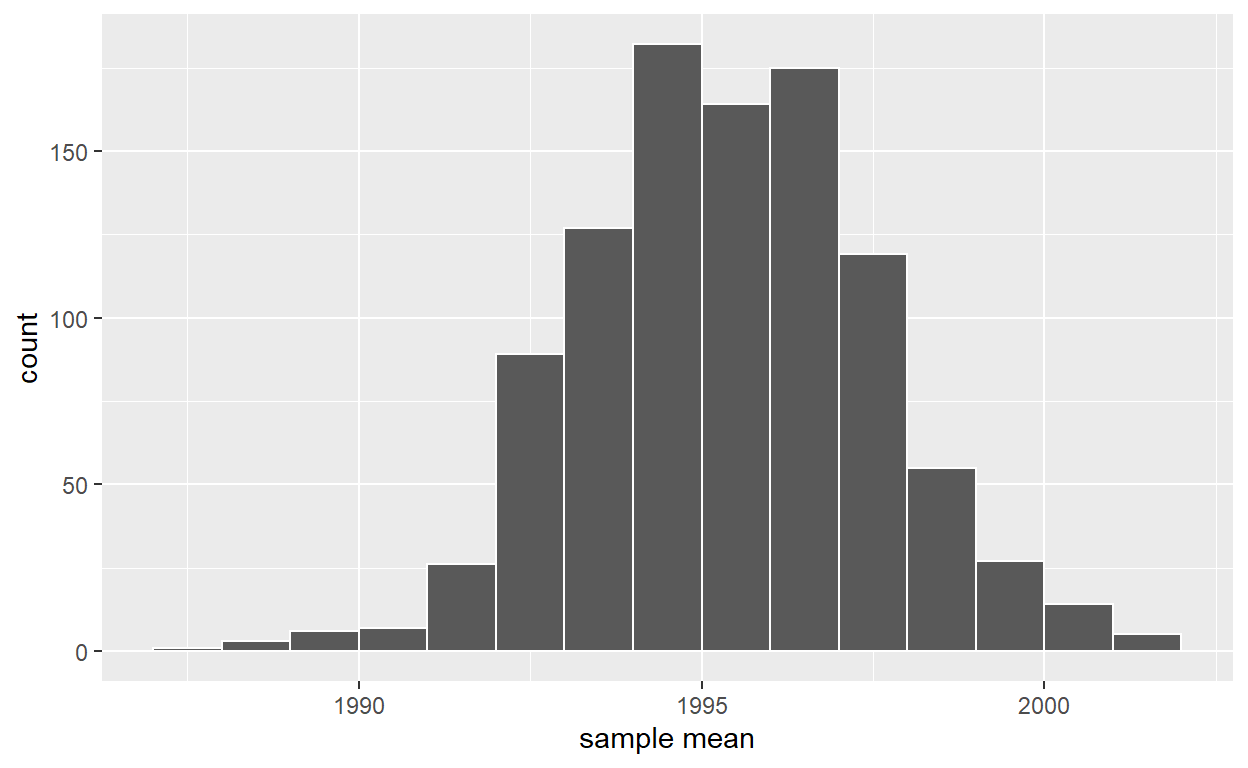
ggplot(virtual_resampled_means, aes(x = mean_year)) +
geom_histogram(binwidth = 1, color = "white", boundary = 1990) +
labs(x = "sample mean")
# A tibble: 1 x 1
mean_of_means
<dbl>
1 1995.
# A tibble: 1 x 1
SE
<dbl>
1 2.12
# A tibble: 1,000 x 2
replicate mean_year
<int> <dbl>
1 1 1994.
2 2 1997.
3 3 1996.
4 4 1996.
5 5 1994.
6 6 1998.
7 7 1995.
8 8 1994.
9 9 1994.
10 10 1999.
# ... with 990 more rows
# A tibble: 1 x 1
stat
<dbl>
1 1995.
Response: year (numeric)
# A tibble: 1 x 1
stat
<dbl>
1 1995.
Response: year (numeric)
# A tibble: 50 x 1
year
<dbl>
1 2002
2 1986
3 2017
4 1988
5 2008
6 1983
7 2008
8 1996
9 2004
10 2000
# ... with 40 more rows
Response: year (numeric)
# A tibble: 50 x 1
year
<dbl>
1 2002
2 1986
3 2017
4 1988
5 2008
6 1983
7 2008
8 1996
9 2004
10 2000
# ... with 40 more rows
Response: year (numeric)
# A tibble: 50,000 x 2
# Groups: replicate [1,000]
replicate year
<int> <dbl>
1 1 2015
2 1 1985
3 1 1978
4 1 1996
5 1 1985
6 1 1974
7 1 1974
8 1 1974
9 1 2002
10 1 1983
# ... with 49,990 more rows
Response: year (numeric)
# A tibble: 50,000 x 2
# Groups: replicate [1,000]
replicate year
<int> <dbl>
1 1 2018
2 1 1988
3 1 1990
4 1 1988
5 1 2015
6 1 1979
7 1 2006
8 1 1993
9 1 1979
10 1 1979
# ... with 49,990 more rows
# Original workflow:
pennies_sample %>%
rep_sample_n(size = 50, reps = 1000)
# A tibble: 50,000 x 3
# Groups: replicate [1,000]
replicate ID year
<int> <int> <dbl>
1 1 31 2013
2 1 23 1998
3 1 39 2015
4 1 45 1997
5 1 32 1976
6 1 33 1979
7 1 38 1999
8 1 35 1985
9 1 7 2008
10 1 1 2002
# ... with 49,990 more rows
Response: year (numeric)
# A tibble: 1,000 x 2
replicate stat
<int> <dbl>
1 1 1990.
2 2 1992.
3 3 1997.
4 4 1996.
5 5 1995.
6 6 1993.
7 7 1995.
8 8 1996.
9 9 1991
10 10 1993.
# ... with 990 more rows
Response: year (numeric)
# A tibble: 1,000 x 2
replicate stat
<int> <dbl>
1 1 1995.
2 2 1999.
3 3 1994.
4 4 1995.
5 5 1996.
6 6 1994.
7 7 2000.
8 8 1996.
9 9 1997.
10 10 1991.
# ... with 990 more rows
# A tibble: 1,000 x 2
replicate stat
<int> <dbl>
1 1 1994.
2 2 1996.
3 3 1995.
4 4 1993.
5 5 1997.
6 6 1996.
7 7 1996.
8 8 1999.
9 9 1994.
10 10 1998.
# ... with 990 more rows
# infer workflow:
visualize(bootstrap_distribution)

# A tibble: 1 x 2
lower_ci upper_ci
<dbl> <dbl>
1 1991. 2000.
visualize(bootstrap_distribution) +
shade_ci(endpoints = percentile_ci, color = "hotpink", fill = "khaki")
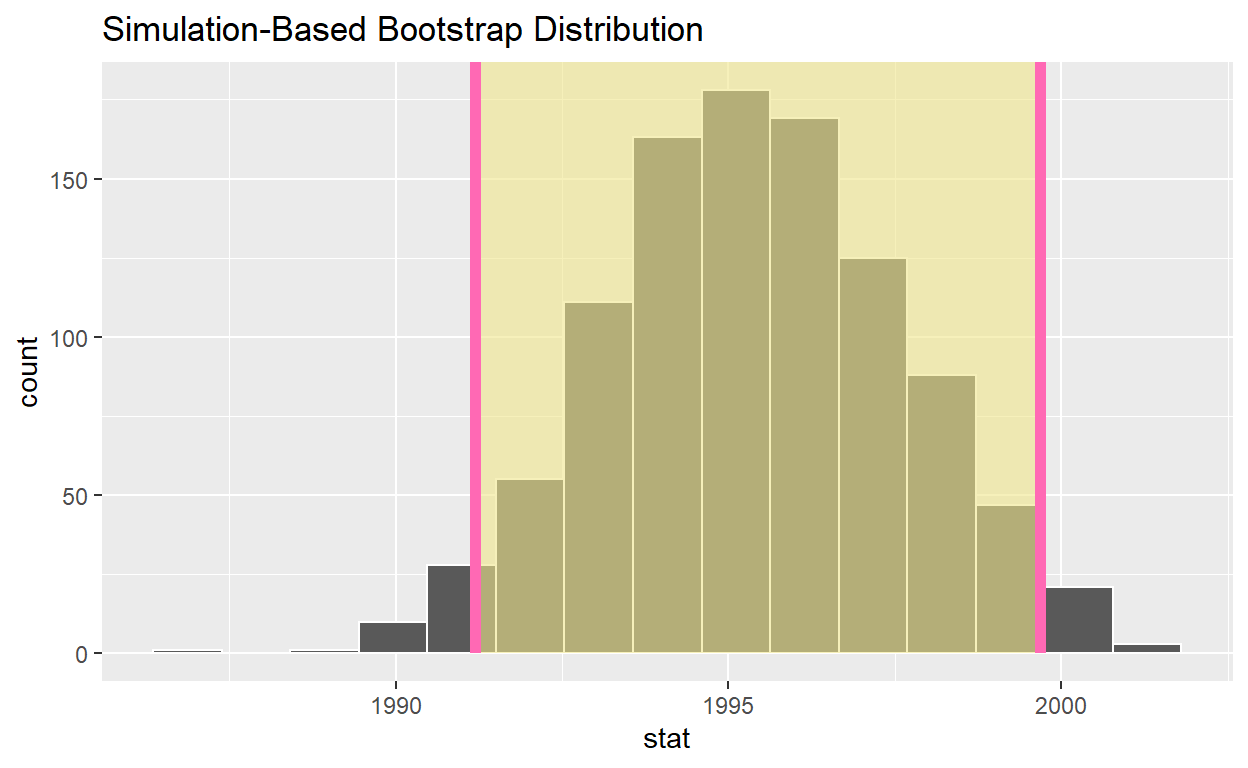
# A tibble: 1 x 2
lower_ci upper_ci
<dbl> <dbl>
1 1991. 2000.
# A tibble: 1 x 1
p_red
<dbl>
1 0.375
sample_1_bootstrap <- bowl_sample_1 %>%
specify(response = color, success = "red") %>%
generate(reps = 1000, type = "bootstrap") %>%
calculate(stat = "prop")
sample_1_bootstrap
Response: color (factor)
# A tibble: 1,000 x 2
replicate stat
<int> <dbl>
1 1 0.52
2 2 0.3
3 3 0.38
4 4 0.38
5 5 0.34
6 6 0.32
7 7 0.46
8 8 0.48
9 9 0.32
10 10 0.4
# ... with 990 more rows
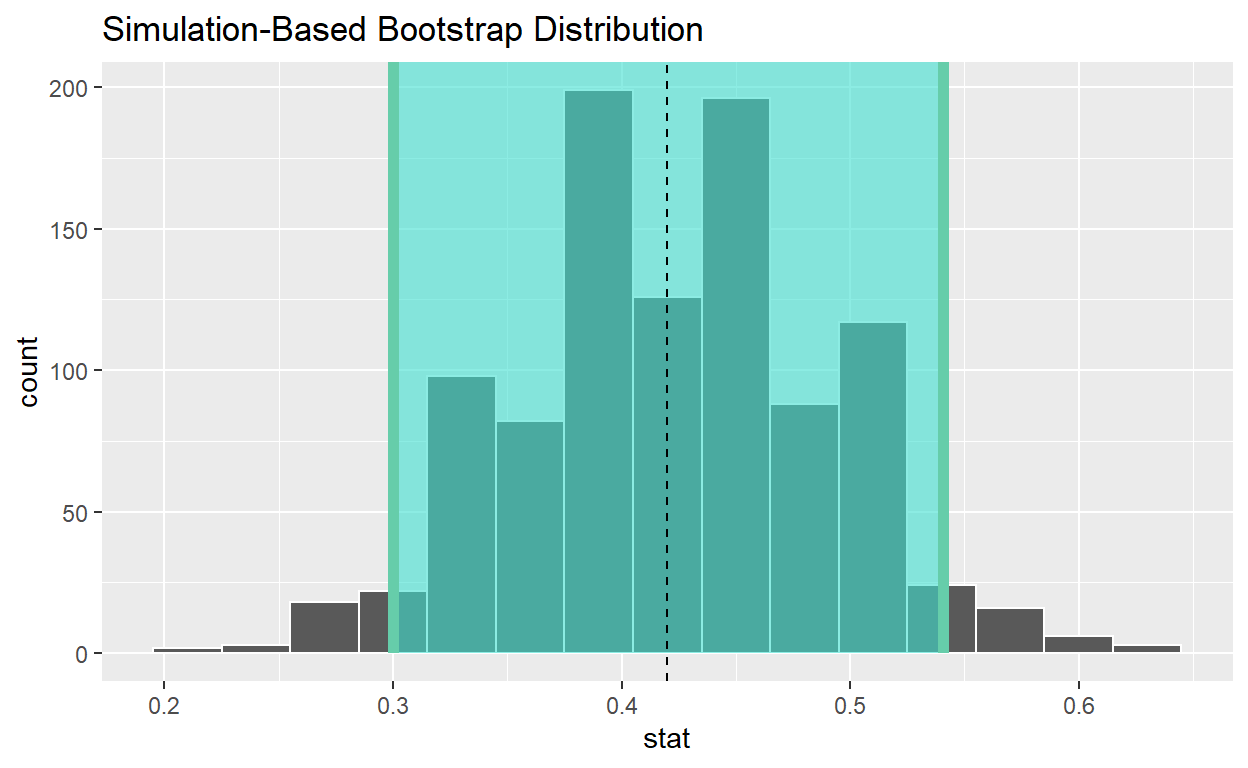
# A tibble: 1 x 2
lower_ci upper_ci
<dbl> <dbl>
1 0.3 0.540
# A tibble: 50 x 3
# Groups: replicate [1]
replicate ball_ID color
<int> <int> <chr>
1 1 1676 red
2 1 511 white
3 1 496 red
4 1 725 white
5 1 2273 white
6 1 90 white
7 1 175 red
8 1 281 white
9 1 317 red
10 1 1504 red
# ... with 40 more rows
sample_2_bootstrap <- bowl_sample_2 %>%
specify(response = color,
success = "red") %>%
generate(reps = 1000,
type = "bootstrap") %>%
calculate(stat = "prop")
sample_2_bootstrap
Response: color (factor)
# A tibble: 1,000 x 2
replicate stat
<int> <dbl>
1 1 0.28
2 2 0.3
3 3 0.32
4 4 0.24
5 5 0.28
6 6 0.28
7 7 0.42
8 8 0.26
9 9 0.36
10 10 0.38
# ... with 990 more rows
# A tibble: 1 x 2
lower_ci upper_ci
<dbl> <dbl>
1 0.18 0.44
# A tibble: 50 x 3
subj group yawn
<int> <chr> <chr>
1 1 seed yes
2 2 control yes
3 3 seed no
4 4 seed yes
5 5 seed no
6 6 control no
7 7 seed yes
8 8 control no
9 9 control no
10 10 seed no
# ... with 40 more rows
# A tibble: 4 x 3
# Groups: group [2]
group yawn count
<chr> <chr> <int>
1 control no 12
2 control yes 4
3 seed no 24
4 seed yes 10
mythbusters_yawn %>%
specify(formula = yawn ~ group, success = "yes")
Response: yawn (factor)
Explanatory: group (factor)
# A tibble: 50 x 2
yawn group
<fct> <fct>
1 yes seed
2 yes control
3 no seed
4 yes seed
5 no seed
6 no control
7 yes seed
8 no control
9 no control
10 no seed
# ... with 40 more rows
first_six_rows <- head(mythbusters_yawn)
first_six_rows
# A tibble: 6 x 3
subj group yawn
<int> <chr> <chr>
1 1 seed yes
2 2 control yes
3 3 seed no
4 4 seed yes
5 5 seed no
6 6 control no
# A tibble: 6 x 3
subj group yawn
<int> <chr> <chr>
1 4 seed yes
2 1 seed yes
3 4 seed yes
4 5 seed no
5 1 seed yes
6 4 seed yes
Response: yawn (factor)
Explanatory: group (factor)
# A tibble: 1,000 x 2
replicate stat
<int> <dbl>
1 1 -0.132
2 2 -0.159
3 3 0.233
4 4 0.0104
5 5 -0.00891
6 6 0.139
7 7 0.206
8 8 0.0190
9 9 0.169
10 10 0.0517
# ... with 990 more rows
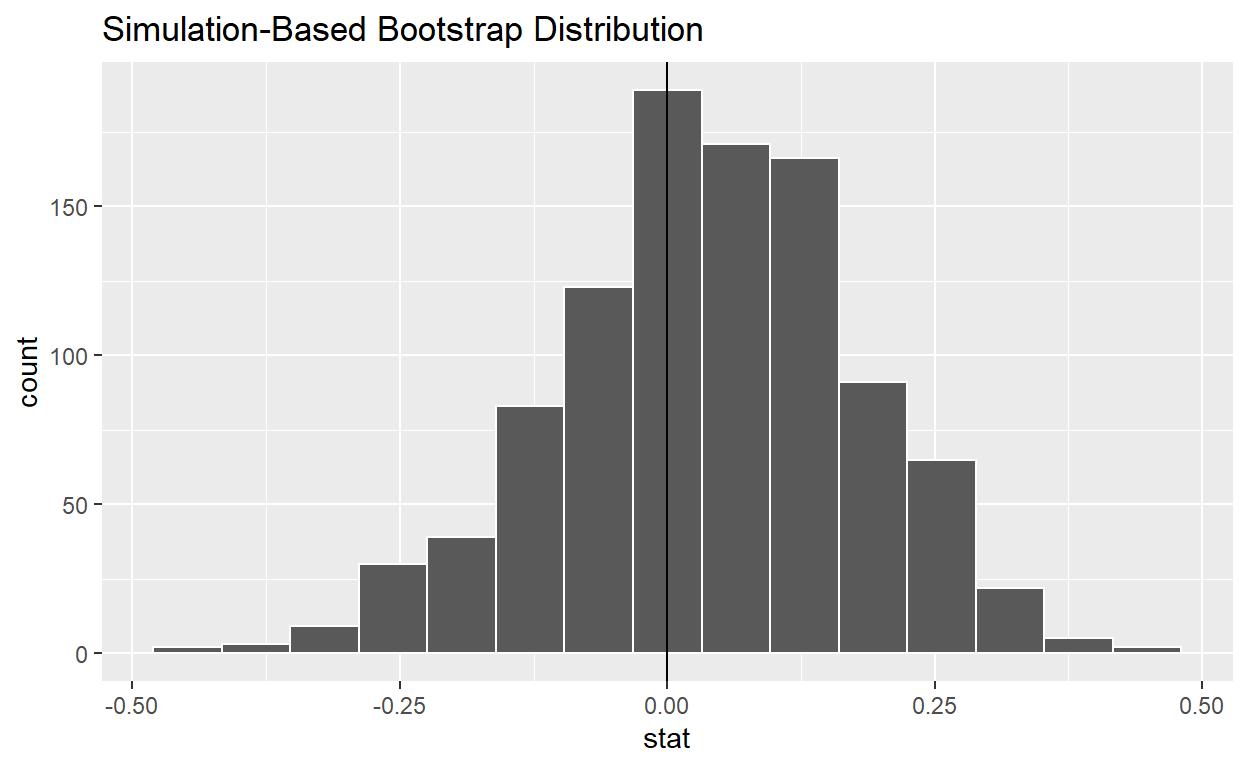
bootstrap_distribution_yawning <- mythbusters_yawn %>%
specify(formula = yawn ~ group, success = "yes") %>%
generate(reps = 1000, type = "bootstrap") %>%
calculate(stat = "diff in props", order = c("seed", "control"))
bootstrap_distribution_yawning
Response: yawn (factor)
Explanatory: group (factor)
# A tibble: 1,000 x 2
replicate stat
<int> <dbl>
1 1 -0.0196
2 2 -0.0920
3 3 0.0833
4 4 -0.123
5 5 0.190
6 6 0.0441
7 7 0.0660
8 8 -0.181
9 9 0.193
10 10 0.166
# ... with 990 more rows
# A tibble: 1 x 2
lower_ci upper_ci
<dbl> <dbl>
1 -0.260 0.291
obs_diff_in_props <- mythbusters_yawn %>%
specify(formula = yawn ~ group, success = "yes") %>%
# generate(reps = 1000, type = "bootstrap") %>%
calculate(stat = "diff in props", order = c("seed", "control"))
obs_diff_in_props
Response: yawn (factor)
Explanatory: group (factor)
# A tibble: 1 x 1
stat
<dbl>
1 0.0441
# A tibble: 1 x 2
lower_ci upper_ci
<dbl> <dbl>
1 -0.231 0.319
# Take 1000 virtual samples of size 50 from the bowl:
virtual_samples <- bowl %>%
rep_sample_n(size = 50, reps = 1000)
# Compute the sampling distribution of 1000 values of p-hat
sampling_distribution <- virtual_samples %>%
group_by(replicate) %>%
summarize(red = sum(color == "red")) %>%
mutate(prop_red = red / 50)
# Visualize sampling distribution of p-hat
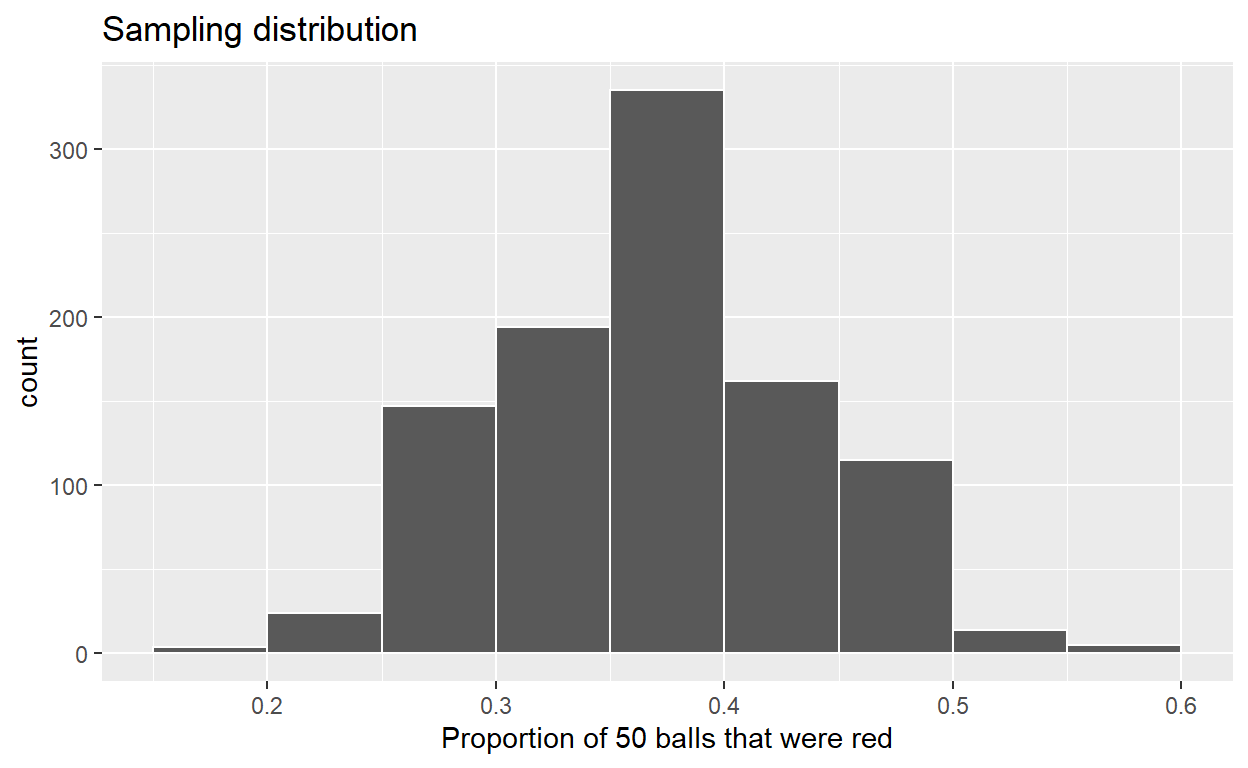
ggplot(sampling_distribution, aes(x = prop_red)) +
geom_histogram(binwidth = 0.05, boundary = 0.4, color = "white") +
labs(x = "Proportion of 50 balls that were red",
title = "Sampling distribution")
# A tibble: 1 x 1
se
<dbl>
1 0.0675
# A tibble: 1 x 1
se
<dbl>
1 0.0708
conf_ints <- tactile_prop_red %>%
rename(p_hat = prop_red) %>%
mutate(
n = 50,
SE = sqrt(p_hat * (1 - p_hat) / n),
MoE = 1.96 * SE,
lower_ci = p_hat - MoE,
upper_ci = p_hat + MoE
)
[1] "[InternetShortcut]\r\nURL=https://fivethirtyeight-r.netlify.app/reference/congress_age.html\r\n"